Künstliche Intelligenz
28.05.2024, 09:01 Uhr
Neuer Benchmark zeigt, was die Sprachmodelle drauf haben
Der neue Test "Needle in a Needlestack" fühlt Large Language Models auf den Zahn. OpenAIs GPT-4o glänzt darin.
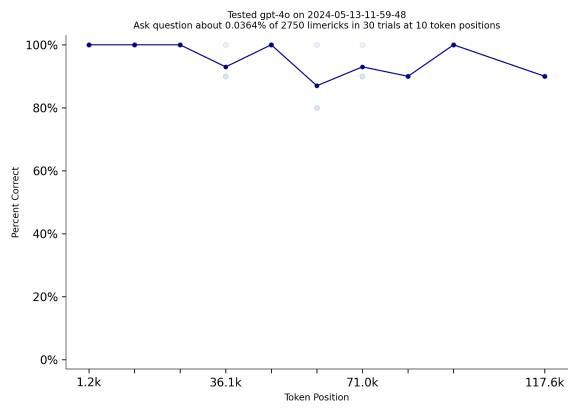
(Quelle: https://nian.llmonpy.ai/)
Mit dem Benchmark "Needle in a Haystack" will man herausbekommen, wie gut Large Language Models (LLMs) wie das von OpenAI oder Google auf die Inhalte im Kontextfenster eingehen. Nachdem aber die LLMs immer besser wurden, reichte der Test nicht mehr aus, um Unterschiede zu zeigen.
Ein neuer Test musste her und das ist Needle in a Needlestack (NIAN). Dazu erzeugt der Test zuerst eine Liste von Limericks aus einer Datenbank von Limericks. Anschliessend stellt der Test eine spezifische Frage zu einem Limerick.
Die bisherigen Sprachmodelle wie GPT-4-turbo kommen bei diesem Test nicht gut weg. Anders sieht das beim neuen Modell von OpenAI GPT-4o aus. Das glänzt in dem Test. Unklar ist, wie OpenAI das erreicht hat.